




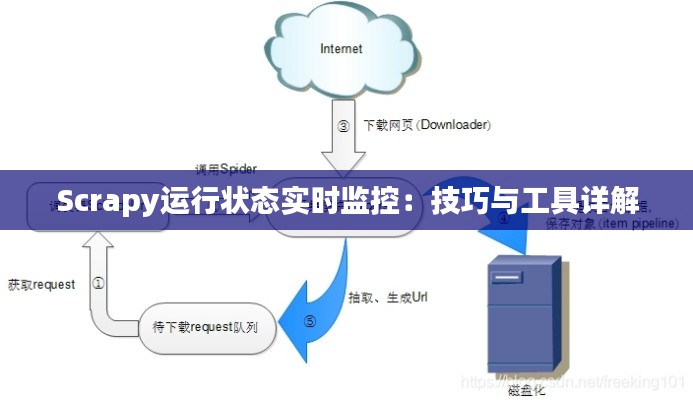
标题:Scrapy运行状态实时监控:技巧与工具详解
随着网络爬虫技术的不断发展,Scrapy作为Python中最受欢迎的爬虫框架之一,被广泛应用于数据抓取领域。然而,在实际使用过程中,如何实时查看Scrapy的运行状态,成为了许多开发者关注的焦点。本文将详细介绍如何实时监控Scrapy的运行状态,包括使用Scrapy内置的统计信息、第三方工具以及自定义日志等手段。
一、Scrapy内置统计信息
Scrapy内置了一套统计信息系统,可以实时查看爬虫的运行状态。以下是如何使用Scrapy内置统计信息来监控爬虫的运行状态:
-
启动爬虫时,使用
-s JOBDIR=your_job_dir参数指定一个工作目录,用于存储爬虫的统计信息。
-
在爬虫代码中,使用
stats对象来访问统计信息。例如:
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = ["http://example.com"]
def parse(self, response):
# 爬取逻辑
pass
def closed(self, reason):
# 爬虫关闭时,打印统计信息
print(self.crawler.stats.get_stats())- 使用
stats.get_stats()方法可以获取爬虫的统计信息,包括爬取的页面数量、下载失败的页面数量、处理失败的页面数量等。
二、第三方工具
除了Scrapy内置的统计信息外,还有一些第三方工具可以帮助我们实时监控Scrapy的运行状态:
-
Scrapy-Redis:Scrapy-Redis是一个基于Redis的Scrapy扩展,可以将爬虫的统计信息存储在Redis中。使用Redis可视化工具(如RedisDesktopManager)可以实时查看爬虫的运行状态。
-
Scrapy-Logstats:Scrapy-Logstats是一个基于日志的爬虫监控工具,可以将爬虫的运行信息实时输出到控制台或文件中。
-
Scrapy-Statsd:Scrapy-Statsd是一个基于Statsd的Scrapy扩展,可以将爬虫的统计信息发送到Statsd服务器,然后使用Grafana等可视化工具进行监控。
三、自定义日志
在Scrapy中,我们可以通过自定义日志来记录爬虫的运行状态。以下是如何使用自定义日志来监控爬虫的运行状态:
- 在爬虫代码中,配置日志记录器:
import logging
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO, filename='scrapy.log', filemode='w',
format='%(asctime)s - %(levelname)s - %(message)s')- 在爬虫代码中,使用日志记录器记录运行状态:
logger.info("开始爬取页面:%s", url)
logger.warning("爬取失败:%s", url)
logger.error("处理失败:%s", url)- 使用日志分析工具(如Logtail)实时查看爬虫的运行状态。
四、总结
本文介绍了如何实时监控Scrapy的运行状态,包括使用Scrapy内置的统计信息、第三方工具以及自定义日志等手段。在实际开发过程中,可以根据需求选择合适的监控方法,以确保爬虫的稳定运行。
转载请注明来自泉州固洁建材有限公司,本文标题:《Scrapy运行状态实时监控:技巧与工具详解》







 闽ICP备2021015086号-1
闽ICP备2021015086号-1