




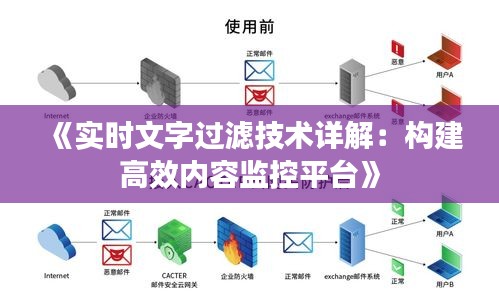
标题:《实时文字过滤技术详解:构建高效内容监控平台》
随着互联网的快速发展,网络信息的传播速度越来越快,内容质量参差不齐,不良信息泛滥。为了构建一个健康、清朗的网络环境,实时文字过滤技术应运而生。本文将详细介绍实时文字过滤的原理、实现方法以及在实际应用中的优势。
一、实时文字过滤的原理
实时文字过滤技术主要基于自然语言处理(NLP)和机器学习(ML)两大领域。其基本原理如下:
-
数据采集:从网络、社交媒体、论坛等渠道收集大量文本数据。
-
数据预处理:对采集到的文本数据进行清洗、去重、分词等处理,为后续分析提供高质量的数据。
-
特征提取:从预处理后的文本中提取关键特征,如词频、TF-IDF、词向量等。

-
模型训练:利用机器学习算法,如支持向量机(SVM)、朴素贝叶斯、深度学习等,对提取的特征进行分类,构建实时文字过滤模型。
-
实时监控:将模型部署到实际应用场景中,对实时输入的文本进行过滤,识别并拦截不良信息。
二、实时文字过滤的实现方法
-
基于规则的方法:通过编写一系列规则,对文本进行匹配和过滤。这种方法简单易行,但规则库需要不断更新,以适应不断变化的不良信息。
-
基于统计的方法:利用文本的统计特征,如词频、TF-IDF等,对文本进行分类。这种方法对规则库的依赖性较小,但准确率受限于特征提取的质量。
-
基于机器学习的方法:利用机器学习算法,如SVM、朴素贝叶斯、深度学习等,对文本进行分类。这种方法具有较好的泛化能力,但需要大量标注数据。
-
基于深度学习的方法:利用深度学习技术,如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等,对文本进行分类。这种方法在处理复杂文本任务时具有较好的效果。
三、实时文字过滤的优势
-
实时性:实时文字过滤技术能够对实时输入的文本进行快速处理,确保不良信息得到及时拦截。
-
高效性:通过机器学习算法,实时文字过滤技术能够自动识别和过滤不良信息,降低人工审核成本。

-
高准确性:随着数据量的积累和模型优化,实时文字过滤技术的准确率不断提高。
-
自适应能力:实时文字过滤技术可以根据实际情况调整模型参数,适应不断变化的不良信息。
四、总结
实时文字过滤技术在构建健康、清朗的网络环境中具有重要意义。本文详细介绍了实时文字过滤的原理、实现方法以及优势,为相关领域的研究和应用提供了参考。随着技术的不断发展,实时文字过滤技术将在更多领域发挥重要作用。
转载请注明来自泉州固洁建材有限公司,本文标题:《《实时文字过滤技术详解:构建高效内容监控平台》》







 闽ICP备2021015086号-1
闽ICP备2021015086号-1