




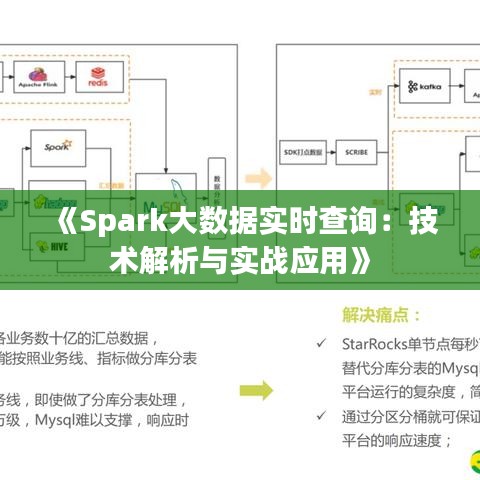
标题:《Spark大数据实时查询:技术解析与实战应用》
随着大数据时代的到来,如何高效处理和分析海量数据成为了企业关注的焦点。在众多大数据处理框架中,Spark凭借其高效、易用、可伸缩的特点,成为了大数据领域的佼佼者。本文将围绕Spark大数据实时查询展开,从技术原理、架构设计、应用场景等方面进行深入探讨。
一、Spark大数据实时查询技术原理
- Spark架构
Spark采用弹性分布式数据集(RDD)作为其数据抽象,RDD是一种容错的、并行的数据结构,可以存储在内存或磁盘上。Spark架构主要由以下组件构成:
(1)Spark Core:提供RDD操作、任务调度、内存管理等核心功能;
(2)Spark SQL:提供SQL查询接口,对RDD进行结构化处理;
(3)Spark Streaming:提供实时数据处理能力,对实时数据进行流式处理;
(4)Spark MLlib:提供机器学习算法库,支持多种机器学习算法;
(5)Spark GraphX:提供图处理能力,支持图算法的并行计算。
- 实时查询原理
Spark Streaming是Spark框架中负责实时数据处理的部分,它通过微批处理(micro-batching)的方式,将实时数据流转换为RDD,然后对RDD进行操作,实现实时查询。实时查询原理如下:
(1)数据采集:通过Flume、Kafka等工具,将实时数据采集到Spark Streaming中;
(2)数据转换:将采集到的数据转换为RDD,进行实时处理;

(3)数据存储:将处理后的数据存储到数据库或文件系统等持久化存储中;
(4)数据查询:通过Spark SQL或其他查询接口,对存储的数据进行实时查询。
二、Spark大数据实时查询架构设计
- 数据采集层
数据采集层负责实时数据的采集,主要包括以下组件:
(1)数据源:如Flume、Kafka等;
(2)数据采集器:负责从数据源中采集数据,并将其转换为RDD;
(3)数据预处理:对采集到的数据进行清洗、过滤等预处理操作。
- 数据处理层
数据处理层负责对实时数据进行处理,主要包括以下组件:
(1)Spark Streaming:负责实时数据处理,将数据转换为RDD;
(2)Spark SQL:提供SQL查询接口,对RDD进行结构化处理;
(3)Spark MLlib:提供机器学习算法库,支持多种机器学习算法。
- 数据存储层
数据存储层负责将处理后的数据存储到持久化存储中,主要包括以下组件:
(1)数据库:如MySQL、Hive等;
(2)文件系统:如HDFS、Cassandra等。
- 数据查询层
数据查询层负责对存储的数据进行实时查询,主要包括以下组件:
(1)Spark SQL:提供SQL查询接口,对存储的数据进行实时查询;
(2)其他查询接口:如JDBC、ODBC等。
三、Spark大数据实时查询应用场景
-
实时广告推荐:通过分析用户行为数据,实时推荐广告,提高广告投放效果;
-
实时监控:对系统、网络、业务等数据进行实时监控,及时发现异常并进行处理;
-
实时数据分析:对实时数据进行挖掘和分析,为决策提供支持;
-
实时机器学习:通过实时数据训练模型,实现实时预测和决策。
总结
Spark大数据实时查询技术在处理海量实时数据方面具有显著优势,能够满足企业对实时数据处理的需求。本文从技术原理、架构设计、应用场景等方面对Spark大数据实时查询进行了深入探讨,希望能为企业在大数据领域提供有益的参考。
转载请注明来自泉州固洁建材有限公司,本文标题:《《Spark大数据实时查询:技术解析与实战应用》》






 闽ICP备2021015086号-1
闽ICP备2021015086号-1